Validator bench
The motivation for this work was to create a software-engineering related benchmark which would produce a numeric, quantitative score for each attempt, rather than a binary pass/fail signal - this way we should be able to get more information out of each run. The plan at this point is to validate the benchmark itself and check that it produces results which ‘make sense’. After that we can cheaply scale and apply it to evaluate impact from smaller-scale changes to models - quantization of weights, kv cache, sampling, etc.
The specific task is to create a validator for TOML 1.0. TOML has a rich set of tests and we can score models according to the number of tests passed. TOML is most definitely known to the models, yet implementing the entire specification correctly for a given TOML version is still non-trivial for many models. In addition, we can also test asking to implement the validator without providing the specification and thus decouple model knowledge and ability to interpret specification and follow directions.
The model is instructed to use the submit() tool to
generate the entire code for a validator. The harness
compiles the code, runs the submitted validator against the test set
and returns the compiler output and/or names of failed tests, if
any. This gives the model partial information on what to fix on the
next turn - no complete test cases, but a hint of what to improve.
Models must use c++ and the exact build command
clang++ -std=c++17 -O2 is shared with the model in the
prompt. The model gets up to 5 turns per attempt.
The benchmark is intended to test the model, not model + some
coding agent combination. The ‘agent’ we have here is rudimentary,
the only tool is submit.
The expectations are different for different classes of models:
- For frontier models, like GPT-5.3-codex or Opus 4.6-4.7 I’d expect them to solve it perfectly or close to that, both in ‘spec provided’ and ‘no spec provided’ variants. It will serve as a sanity check for a benchmark, rather than a differentiator between frontier models, so I planned to run it for just 3 attempts each.
- The second tier was Sonnet 4.6, Sonnet 4.5 (September 2025) , GLM 5.1 and Kimi K2.5. GLM 5.1 and Kimi K2.5 are the first open-weight models which felt close to ‘frontier several months ago’, while still not quite on modern Opus level. I expected these models to do well, but not perfect. I decided to run 15 attempts; I also included Qwen 3.6 Plus in this category, even though I have no experience with this model.
- The third tier was strong open-weight models which are practical to run locally. Here I was interested in different quantization level performance, and focused on larger members of the Qwen 3.5 family - 397B and 122B MoE models. I decided to run 20 attempts each only for ‘spec’ variants; the expectation here was that I should be able to notice the difference between quant levels, thus more runs.
Inference providers used:
- OpenAI for GPT-codex
- Anthropic for Opus/Sonnet
- Fireworks for GLM 5.1, Kimi K2.5 and Qwen 3.6 Plus
- Local llama.cpp build for Qwen 3.5 quantized models (122B-A10B GGUF and 397B-A17B GGUF)
As we ask models to create a validator which returns true/false, we are creating a binary classifier. This means, if we just count the number of tests passed, the trivial baseline ‘always return true’ or ‘always return false’ would get pretty decent results. Instead of using test pass rate, I use MCC. It is computed from the confusion matrix as
mcc = (tp * tn - fp * fn) / sqrt((tp + fp)(tp + fn)(tn + fp)(tn + fn))The perfect classifier would score 1, the ‘perfectly wrong’ -1, and 0 is ‘as good as random’.
Here are the results for ‘best of 5 turns’ for a ‘toml specification provided’:
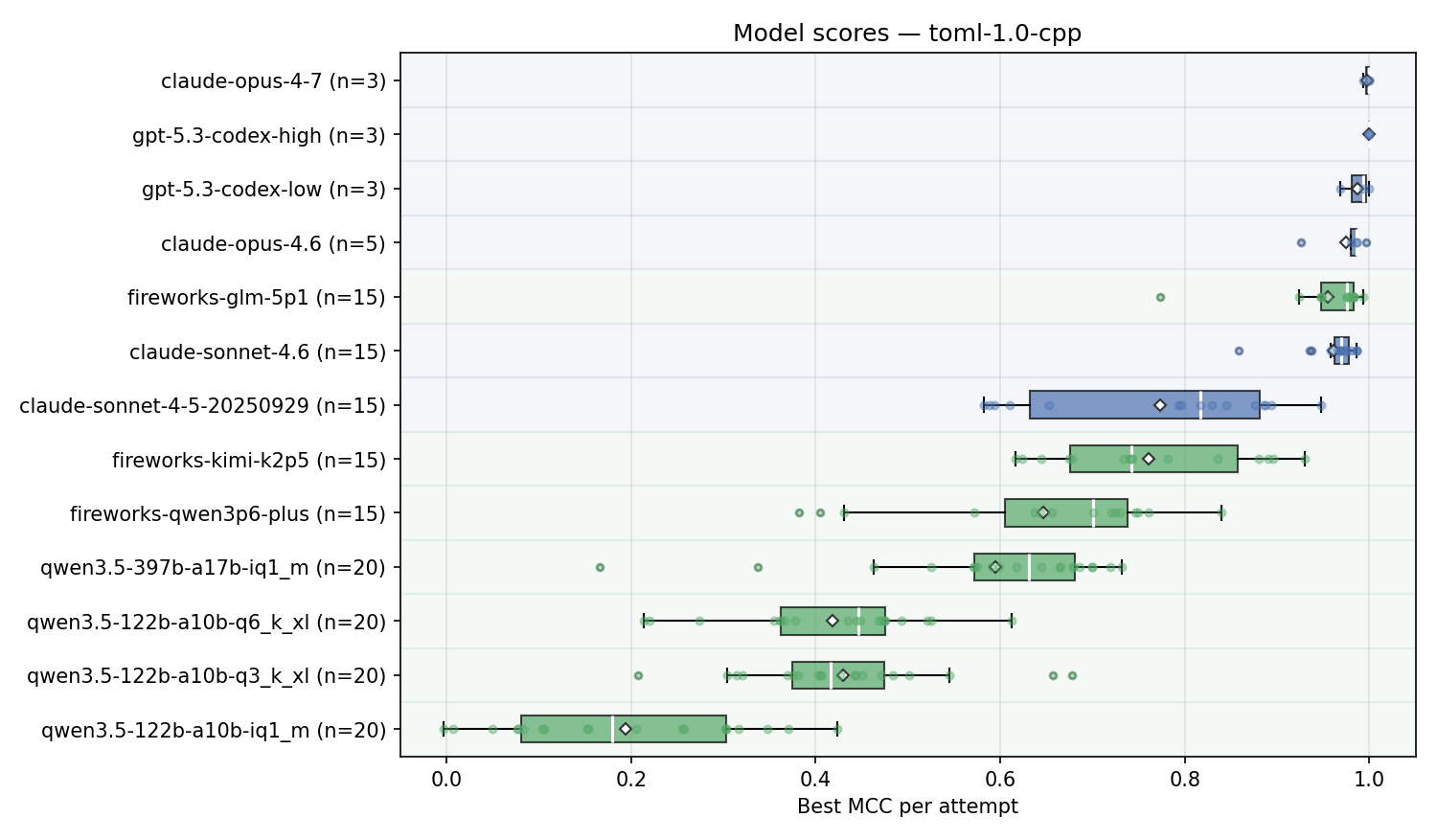
Observations:
- Frontier models do indeed solve it, with GPT-5.3-codex-high and Opus 4.7 consistently getting perfect scores, so benchmark passes sanity check;
- GLM 5.1 is very close to Sonnet 4.6 and considerably stronger than Sonnet 4.5, released 2025-09;
- Kimi K2.5 is very close to Sonnet 4.5
- Larger model, more aggressive quant vs smaller model, less aggressive quant: Qwen 397B @ IQ1, 107GB is stronger than Qwen 3.5 122B @ Q6, 112GB.
- For Qwen 3.5 122B there’s no strong difference between Q6 & Q3, but IQ1 quality drops sharply
- Qwen 3.6 Plus, which is slightly better than 3.5-397B on self-reported results, scores slightly better than the IQ1 quant of the 397B version;
- The range with the ‘recommended’ temperature settings is pretty wide;
Now let’s take a look at how the score changes for the ‘no specification provided’ case. I only ran it for the stronger models.
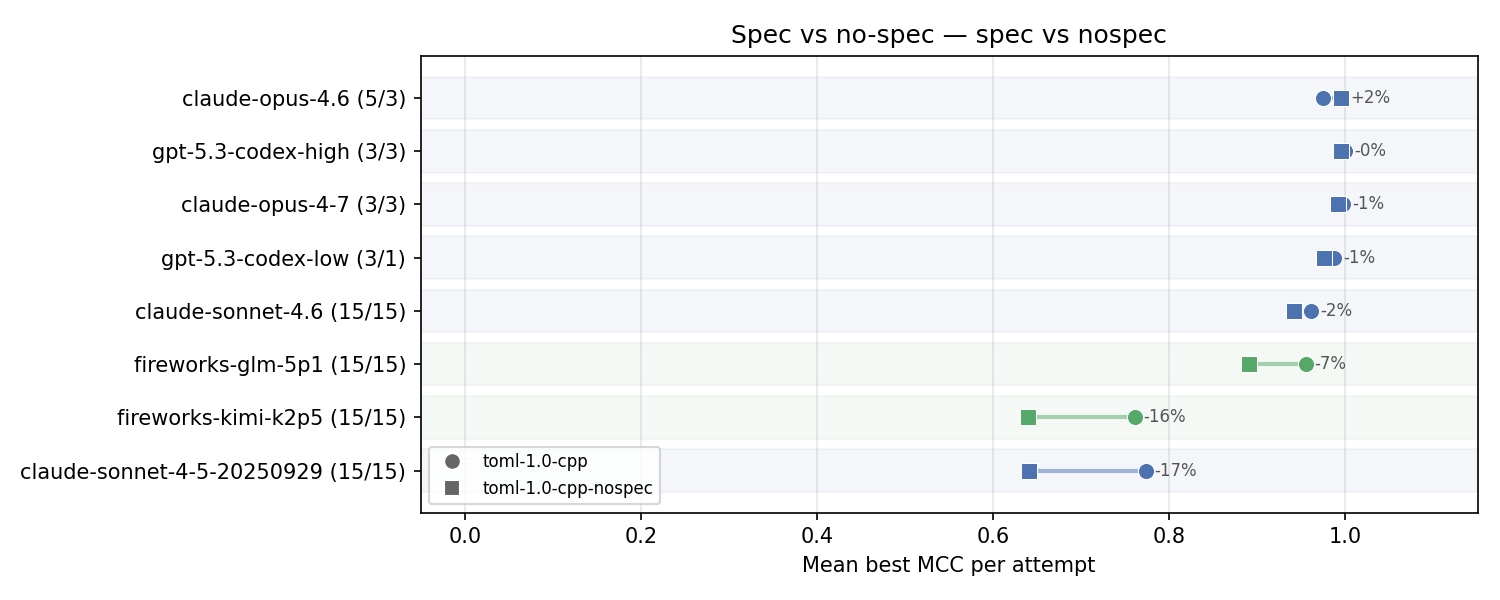
Top models are still doing great, they have enough knowledge and/or reasoning ability to recover from partial mistakes on early turns to get close to perfect scores.
Sonnet 4.6 sees a small drop, while GLM 5.1, Sonnet 4.5 and Kimi K2.5 see fairly substantial ones.
Interestingly, GPT-Codex often gets compile errors on the first
few turns - it consistently tries to include non-standard
<bits/stdc++.h> header, despite being provided
with the exact build command we are going to use. I suspect this is
coming from some competitive programming training data.
Let’s also take a look at the latency, with focus on models from the same provider - Fireworks.
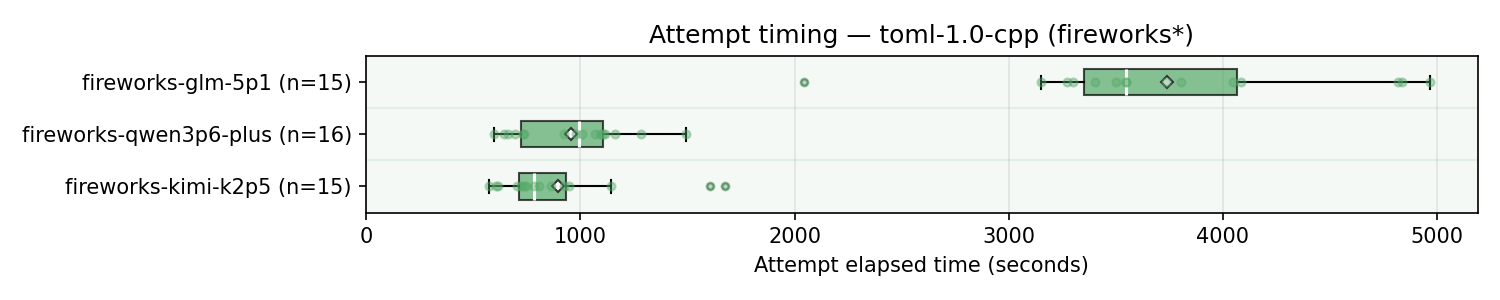
As we can see, GLM 5.1 is much slower compared to Kimi K2.5 and Qwen 3.6 Plus. I don’t have the exact token information saved, but it was coming from both slower time per token and more thinking tokens.
Next steps
- Visualizing by-turn improvement. (Update)
- Create a more challenging version of the benchmark which would be useful to differentiate between frontier models; One straightforward way might be to use much more obscure programming languages, potentially supplying language specification in the prompt; (Update)
- Create more tasks for different formats; This way we can easily get more data for |tasks| x |language|.
- Run on more quantized versions of existing mid-tier models - for example, where exactly a drop in Qwen 3.5-122 score happens?
- Run on new models are they are released - Kimi K2.6 seems to be released right now;(Update)
- Run with KV-cache transfer for models where we see the impact of quantization, like Qwen 122B
References:
- Benchmark source code (llama-sandbox/validation-bench)
- Qwen 3.6 announcement
- GLM 5.1 announcement
- Claude Opus 4.7 announcement
- GPT-5.3-codex announcement
- GLM 5.1 on Fireworks
- Qwen 3.6 Plus on Fireworks
- Kimi K2.5 on Fireworks
- Kimi K2.5 on Hugging Face
- Unsloth Qwen 3.5 122B-A10B GGUF
- Unsloth Qwen 3.5 397B-A17B GGUF