Validator Bench: Best-of-N, GPT-5.5
Previous results may suggest that this variant of the benchmark is close to saturation - opus 4.7 and gpt codex 5.3 are able to get perfect scores.
There are, however, multiple angles to it. First, we were looking at a single combination of language to validate (toml) and language to use for implementation (c++17). On top of that, we were fairly generous with the budget - we let the model use 5 turns per attempt to fix the issues. While the results for more language combinations are backfilling, let’s take a closer look at by turn improvement for toml-1.0-cpp task. We still pretty much ignore the token cost for now, we’ll dive deeper into that once we have more tasks ready and running.
Scoring by turn is more complicated to interpret. As we use MCC as our metric, the lowest score is -1. How should the compile error or failure to submit be evaluated? Negative one implies being confidently wrong, while zero would be equivalent to random/trivial scoring.
To show the difference and progress, we decide on score buckets, and show progression - how likely are we to get a submission of score within that bucket for a given turn.
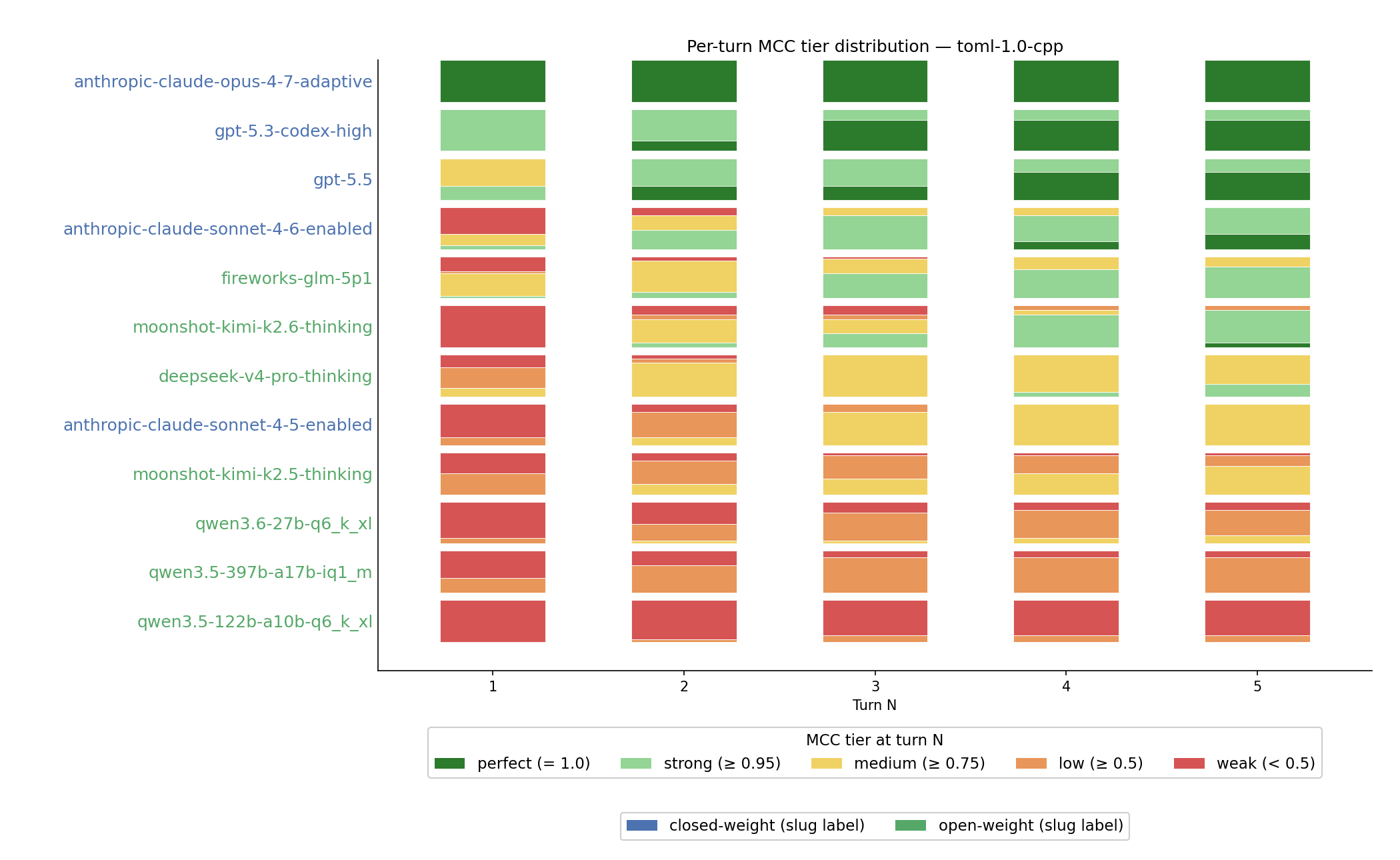
We can make some observations from this single chart:
- Opus 4.7 is consistently one-shotting the task on the very first turn;
- OpenAI models (gpt-5.3-codex and the recently released GPT-5.5) often would reach perfect submission by turn 5;
- Sonnet 4.6 is slightly better than top open-weight models;
- Kimi K2.6 shows the most drastic progression - it fails to submit anything on first turn because of overthinking, but gets very good scores on later turns;