Validator Bench: Kimi K2.6, DeepSeek V4, Qwen 3.6
This is a small update for Validator Bench.
The task stays the same, create a validator for TOML 1.0 using c++17. The motivation for now is to get it into stable condition for this one task, and then quickly scale to many more tasks with the same basic property - providing real value score rather than binary pass/fail to gain more information per sample, thus being more efficient in estimating model ability.
One change is for the benchmark harness itself - separate runners for different model providers, as there are different settings which make litellm-based harness way overloaded and bug-prone.
Other changes involve running for newly released models.
Here’s the overall summary for the results. Note that there are multiple entries for models like Opus 4.7 - the old one from deprecated litellm-based runner and new ones from dedicated Anthropic SDK runner with correct thinking budget setting. In the next run, we’ll clean up old results. Some runs are still in progress and will be updated for completeness, yet I do not expect the results for this task to change significantly.
In the chart below, color coding distinguishes open-weight from proprietary models, and model names in bold are the ones newly added in this update.
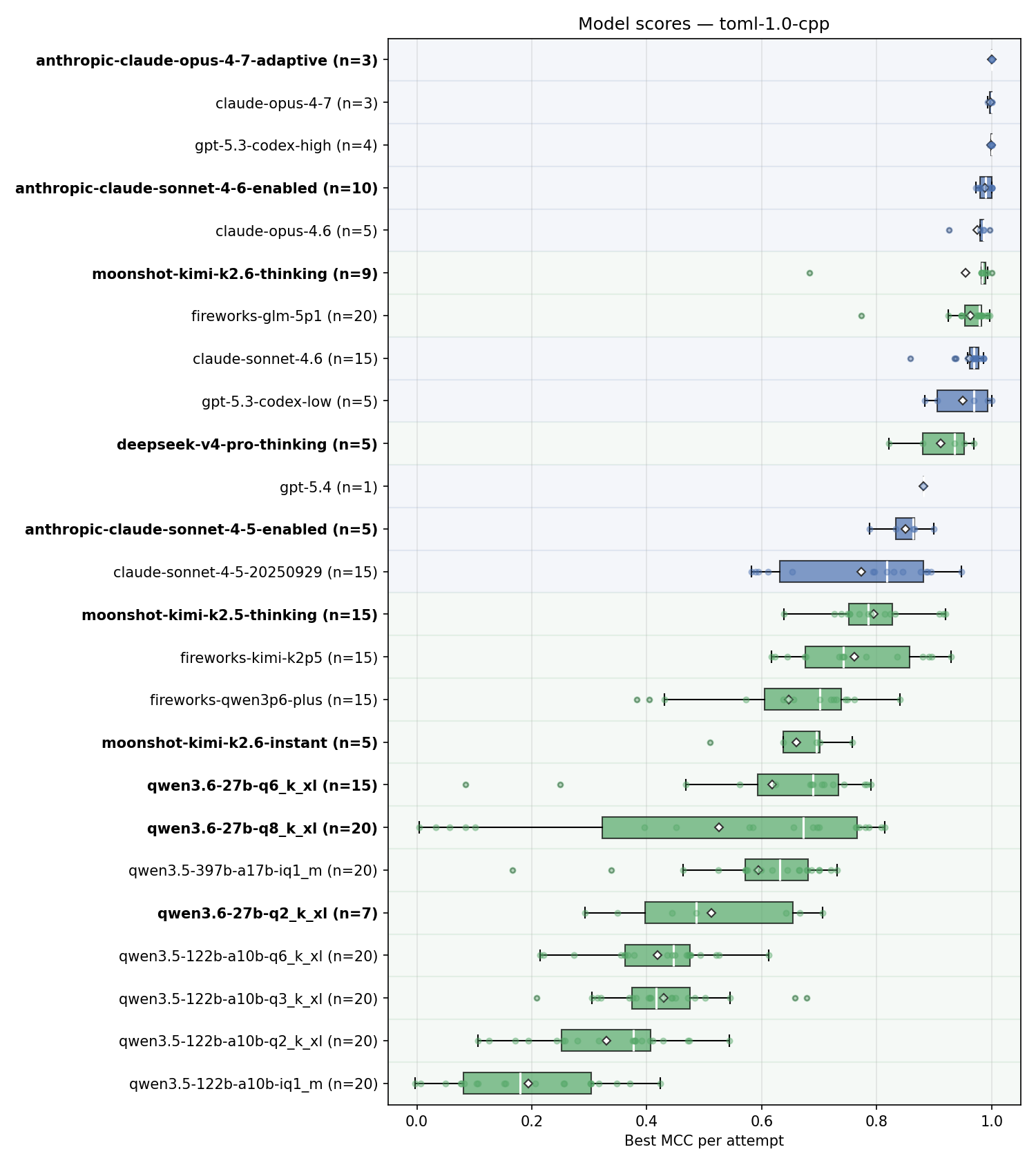
Observations:
- Running Opus 4.7 with official Anthropic SDK and adaptive thinking results in it completing the task with perfect score on first turn; No other model did that - gpt-5.3-codex with high thinking got to perfect score after several turns;
- Sonnet 4.6 with thinking budget of 30000 bumps its score as well;
- Kimi K2.6 is extremely good when it actually submits something, it is the only open-weight model which got a perfect score on at least one attempt. However, it has one very weak submission and multiple complete failures to submit anything. It’s hard to decouple at this point if it’s the issue of the API provider, the model itself or potentially some misconfiguration. For example, in some cases the model kept thinking for > 100k tokens on first turn, a dedicated thinking budget would help here. these completely failed attempts are not shown on the chart;
- DeepSeek V4 seems good on this task, but not at the top level;
- Qwen 3.6-27B is very strong. It’s obviously not in the same league as the frontier models, but for a tiny model which can easily fit on a single consumer GPU it does a very good job and retains a large fraction of its performance when quantized. More tests for this model are coming;