Validator Bench: YAML 1.2
TOML parsing seemed to be pretty easy for top-tier models, with Opus 4.6-4.7 and GPT 5.3+ hitting a perfect score. Good open-weight models were also fairly strong, reaching 0.9+ MCC, and Kimi K2.6 achieved a perfect score on one of the attempts.
Compared to TOML, getting a compliant YAML parser is considerably harder - there are many more corner cases to consider.
I used libfyaml as the reference YAML parser and the yaml-test-suite as the test suite.
Same as with TOML, I fully expect the models to be aware of the YAML format, specification, and implementations. Still, as we can see, getting a good implementation is hard.
Just as before, the model’s task is to write a validator. To better distinguish between ‘validator thinks YAML is invalid’ and ‘validator crashed’, the expectation is that the validator returns 0 and prints its verdict to stdout.
For each attempt the model can do up to 5 submissions and will get test names and outcomes on failure - so, partial information about which tests to fix, no full test leakage.
Each dot is the best MCC score out of 5 turns per attempt. A perfect validator would score 1, random - 0, a perfectly wrong validator would get -1.
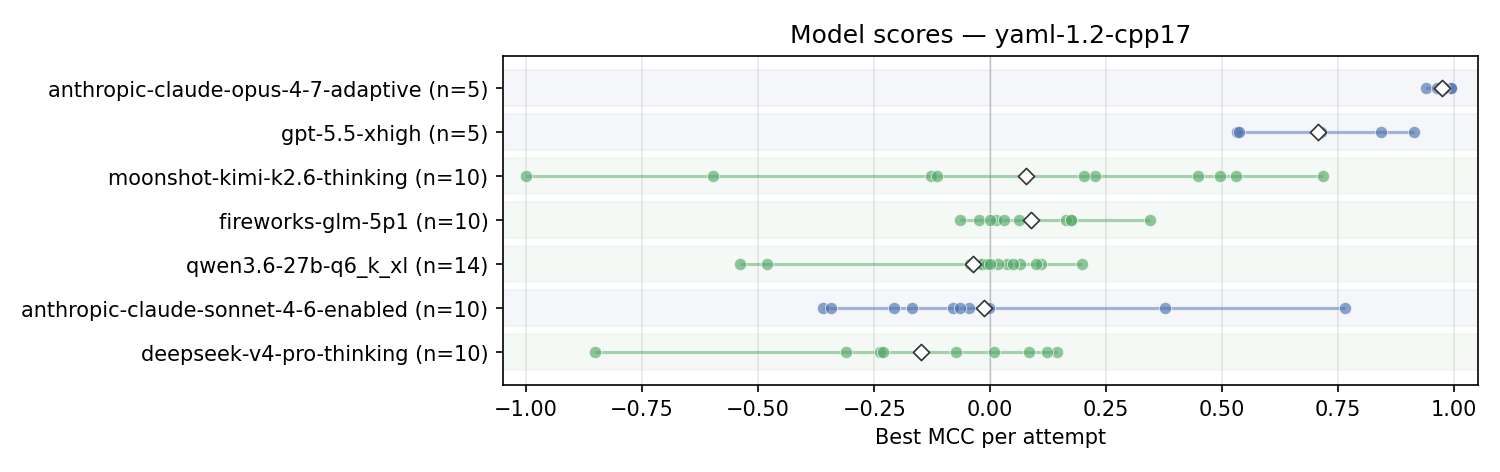
I ran each model 5-10 times, so a boxplot would add more noise than value, and we can just look at individual submissions.
- Opus 4.7 does well, with one of the attempts getting all samples but one correct. For details on that sample and repro/validation, see the strongest Opus 4.7 attempt;
- GPT-5.5 x-high also does well; some failed examples are studied;
- As before, Kimi K2.6 appears strong but inconsistent. Some attempts score pretty high, others are very weak - including what looks like a ‘perfectly wrong’ submission. It is, however, just timing out on every sample, so our scoring gives it an ‘incorrect’ verdict; this is not a case of a swapped label. See the infinite-loop repro;
- As before, the GPT model seems to be using
competitive-programming patterns. The
code is not very readable and still includes the non-standard
<bits/stdc++.h>. Now that the harness runs in a more forgiving Docker environment with g++, it actually does work; - Other models are not doing well. Sonnet 4.6 has some similarity to Kimi K2.6, with a few ‘good outliers’. No other model shows consistently strong results;
Next steps
- I’ve started implementing and testing more targets and languages - lua, golang, etc.;
- Before that, however, we need to optimize the harness itself - batched evaluation, multi-threaded evaluation of the tests themselves, so that the harness isn’t blocked on a timeout in each test case;
References
- Benchmark source code (llama-sandbox/validation-bench)
- libfyaml - compliant YAML parser
- YAML test suite
- YAML 1.2 specification
- Validator Bench (original)
- Validator Bench 0.0.2
- Validator Bench 0.0.3
- Kimi K2.6 announcement
- GPT-5.5 announcement
- Opus 4.7 strongest attempt (repro)
- GPT-5.5 failed example (repro)
- Kimi K2.6 infinite-loop (repro)