Validator Bench: Leaderboard
More context about the benchmark setup can be found here, with a per-step study here and the YAML task description and corner cases here. Briefly: the model needs to implement a validator for some language (JSON, TOML, etc.) according to a specification, and is scored based on its performance on a predefined test set with hundreds of test cases.
The benchmark tests a combination of entities across several dimensions:
- ‘model’ - tries to solve the problem. It can be further broken
down by quantization level, inference engine, sampling settings,
reasoning settings, etc., but for now it’s considered a single flat
entity, for example
anthropic-claude-opus-4-7-adaptive,gpt-5.5-xhighorqwen3.6-27b-q4_k_xl. The ‘agent’ is minimal - the goal is to test the model itself. - ‘task’ or ‘spec’ - what does the validator need to validate? For example, TOML 1.0, YAML 1.2, HCL 2 or Sqlite SQL dialect.
- ‘environment’ - where and how is the solution submitted by a model built and run? Currently, it’s a set of programming languages - C++, Zig, etc. Models are allowed to use the standard library for the language, but no external packages.
We fully expect models to know what YAML or C++ is. Some of the tests might also have been seen by the model in training data. Unless models cheat by hardcoding answers (not a single case like that was found by spot checks), we can still make some useful observations about model’s performance; it’s hard to make generalization claims anyway for any existing coding benchmarks like SWE-bench Verified.
Leaderboard
This is a leaderboard for 6 selected models and (TOML-1.0, YAML 1.2, HCL 2) x (with-specification, without-specification) x (C++17, zig) set of tasks. For each task the model gets multiple independent attempts, so we can understand the variance within a task.
| model | P(acc≥0.90) | P(acc≥0.99) | P(acc≥1.00) |
|---|---|---|---|
| opus-4-7-adaptive | 0.850 | 0.717 | 0.528 |
| gpt-5.5-xhigh | 0.706 | 0.642 | 0.567 |
| sonnet-4-6-enabled | 0.631 | 0.200 | 0.033 |
| glm-5p1 | 0.533 | 0.250 | 0.150 |
| deepseek-v4-pro-thinking | 0.363 | 0.071 | 0.037 |
| kimi-k2.6-thinking | 0.304 | 0.044 | 0.000 |
In the previous notes about this benchmark we used MCC; for these charts we look at mean accuracy. As we mostly focus on the higher end (90%+ of tests passed), this is fine and easier to reason about — a trivial baseline (always return true/false, or return random verdict) is not going to score over 90% on the test suites.
The way to read the data: how likely is a model to produce a classifier (validator) with accuracy >= x for a task/environment from the dataset?
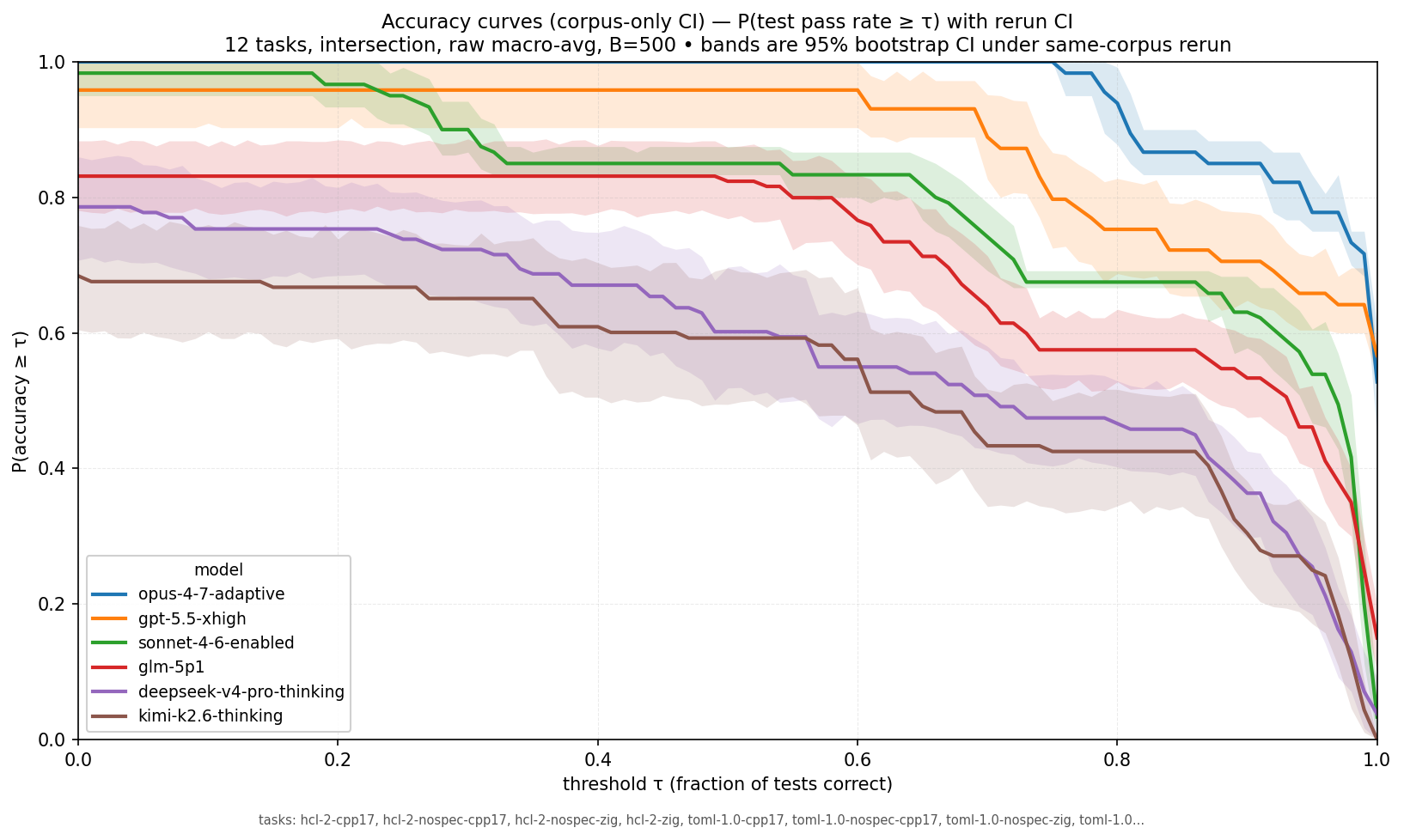
Confidence intervals here should be understood like this: if we rerun the same set of tasks on fresh attempts, in 95% of cases we’d expect the P(mean_accuracy > threshold) to be within the interval. It’s not a confidence interval for an ‘arbitrary validator in an arbitrary environment we might ask a model to build’.
Observations:
- Opus generally dominates, but for a ‘perfect’ solution GPT 5.5
overtakes it. This means Opus is more likely to build a validator
that gets 99% of cases right, but GPT 5.5 is more likely to build a
perfect validator. It is within the intersection of the confidence
intervals and not conclusive, though. An example of an
almost-perfect Opus submission which affects the ranking at the top:
solution.
It allows numeric literals like
1.2.3. - Sonnet has a massive decline at p99 -> max — similar to Opus, but even more dramatic.
Breakdowns
We can also plot a similar chart to understand language/environment breakdown; it will be a combination of a model’s proficiency with a language and that language/stdlib’s suitability for the task.
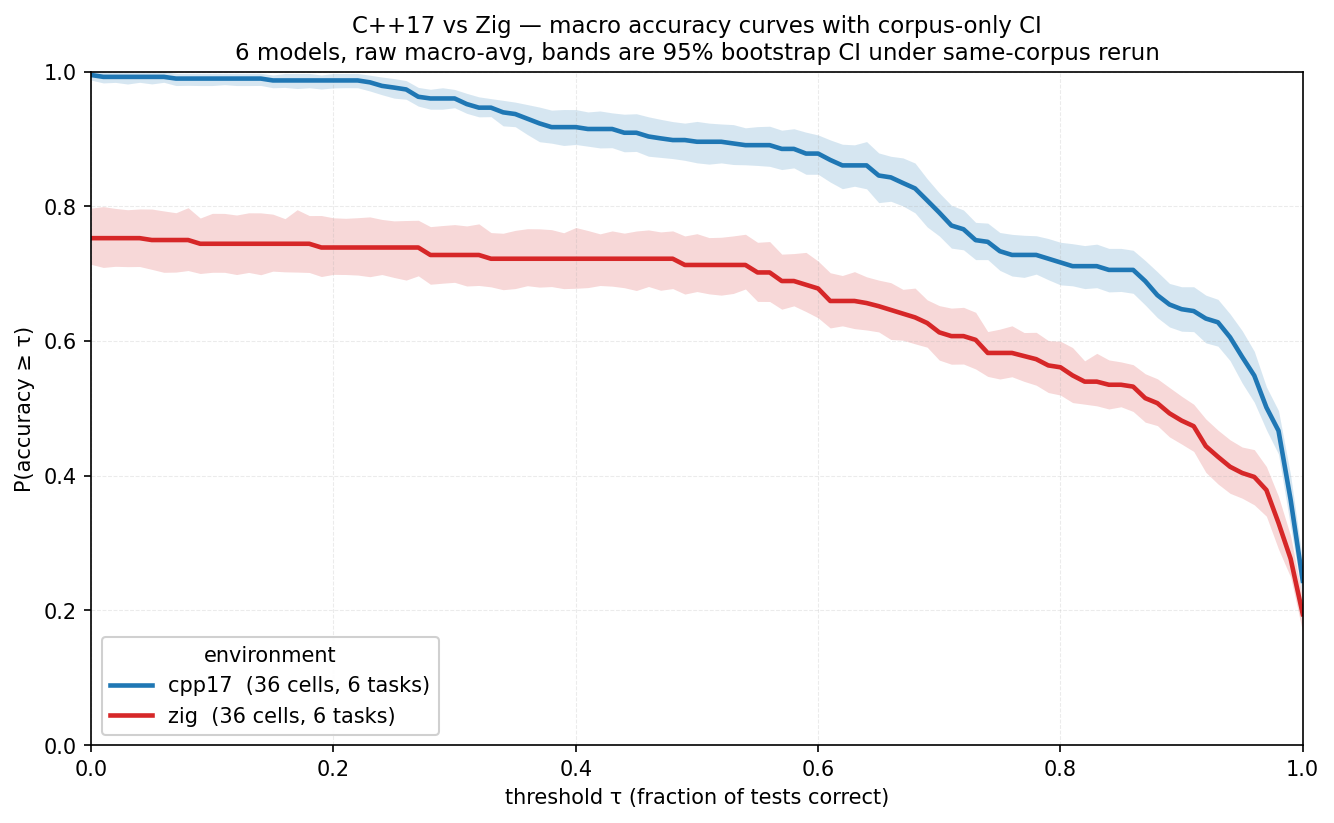
We can clearly see that C++17 is an easier language for these models/tasks.
Here’s a breakdown by task - what language do we need to validate. YAML is a clear outlier here, while TOML and HCL are fairly attainable to ~90% accuracy.
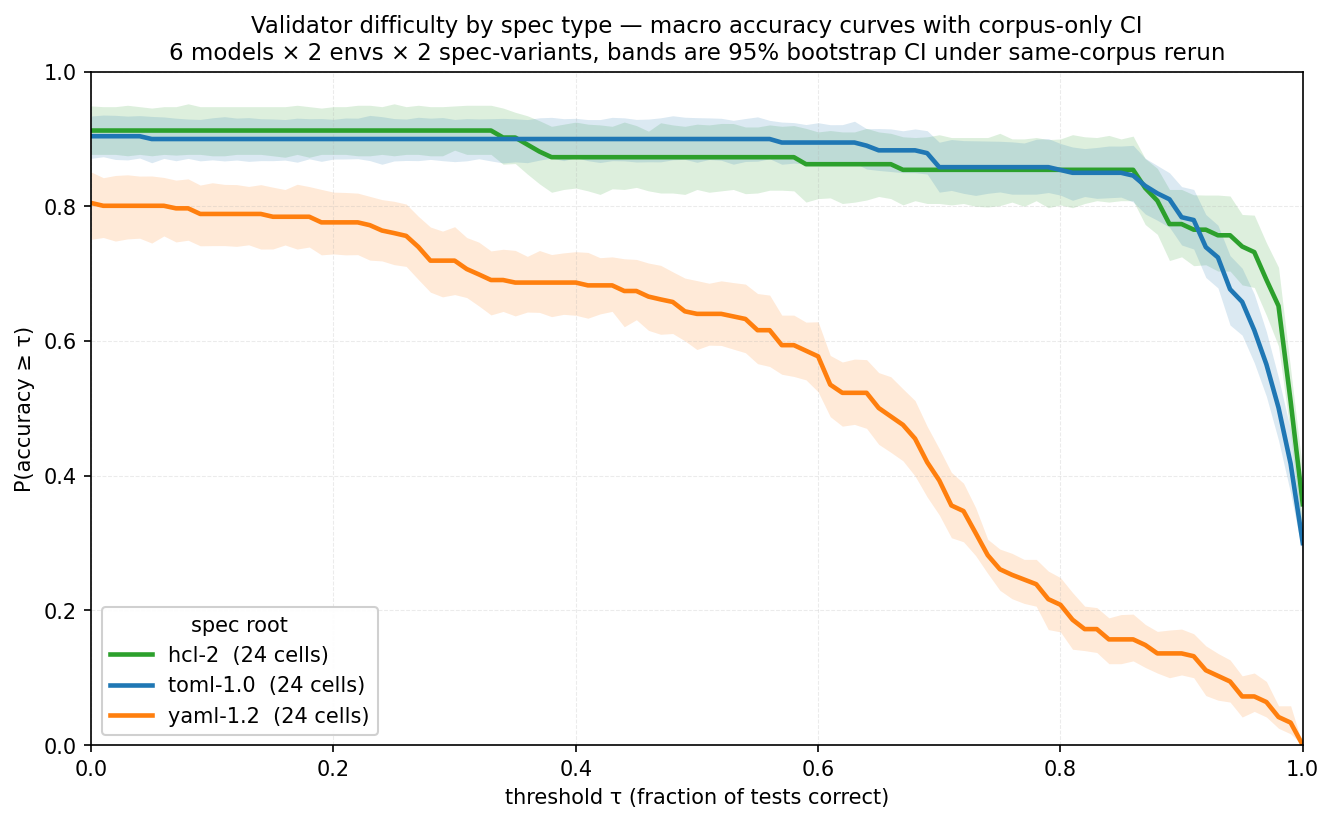
We can see a big gap here and more target languages will definitely help: easier languages (like JSON) for smaller, weaker models and harder for stronger models.
Moving to one shot
After experimenting with this benchmark, I’m considering simplifying it further to avoid multi-turn submissions entirely. This would get rid of failures due to exceeding the context window, simplify the data studies, allow batch processing of requests so we can submit them in a batch with shared initial prompt, give better kv-cache hit rates, avoid the possibility of leaking information about tests, and further decouple the model from the coding agent — there’d be no ‘agentic loop’ at all.
Plans for the one shot:
- We’ll need to rewrite the prompt, as currently models are explicitly told that they’ll get a chance to resubmit and fix compile errors, for example.
- Still testing the model, not the agentic harness/coding agent. The idea is to decouple the two and focus on tasks the model should be able to do without much exploration. Input and expected output must fit into the context window comfortably;
- Simplicity: easy enough to reason about tasks and submissions, and check for errors;
- Being useful for a broad set of models - from frontier to quants of smaller open-weight ones, which will require a broader spec selection and implementation language selection;
- Being able to evaluate the complexity of tasks and environments,
not only do model A/B testing; we should be able to learn that
format
foois harder to parse for a given model than formatbar, or that using languagebazfor implementation is hard. This can guide further benchmark development and potentially model training data selection; - Cost efficiency: current top models like Opus 4.7 are pretty expensive to run. With one-shot we’ll be able to use batch processing efficiently, make sure prompt caching is utilized, generate many outputs from a single prompt to understand the variance. We can also share the bulk of the prompt (specification/task) between implementation languages and only modify language-specific instructions (‘use C++17’ or ‘use Rust’).
- Adaptively pick how many independent attempts for (model, task, environment) we need to run to maximize new information gain; There are definitely (model, task) cells where we get results quickly and consistently.
- Writing tests as another benchmark. Another aspect of both benchmarking and test set generation could be to ask models to find counter-examples for some set of submitted solutions, reference implementation and specification. We can rank the models by their ability to find these test cases, as well as build a stronger test corpus;
References
Prior notes in this series:
Specifications and tooling:
- TOML 1.0 specification
- YAML 1.2 specification
- HCL 2 specification
- Benchmark source code (llama-sandbox/validation-bench)
Models: