Using Claude Code, April 2026
AI-assisted coding evolves so fast that I’m starting to forget how it looked 6 months ago. I’ll try to make these writeups ~monthly to be able to go back and appreciate the progress.
The concrete project here is a KV-cache transfer experiment for locally-running language models. You can find the results in part 1 and part 2 (Gemma 4).
Setup
- Claude Code Max subscription with 1M context window, Opus 4.6;
- GitHub repo with my code - a collection of independent but conceptually connected experiments that share similar structure and build commands;
- local llama.cpp
checkout, added via
/add-dir- used as a library, not modified, but Claude needs access to the source to understand the API.
Overall approach
It is very tempting to just let it run and do everything end-to-end, yet I’m still not comfortable shipping code I’ve never read. At the same time, for experimental projects like this one, thorough review at every step is a waste of time. For ‘large features’, like the very first version of the experiment, I split the work into two phases.
Phase 1: iterate. Create a branch
(foo), let Claude Code run without reviewing the code,
test the outcome, iterate until results make sense. A lot of code
gets removed or rewritten - for example, I went through multiple
iterations on chart generation before the visualizations looked
clear. Reviewing code at this stage would be wasted effort since
most of it gets thrown out.
Phase 2: review. Once the feature works, create
a second branch (foo-rc) and ask Claude Code to look at
the diff between main, foo, and
foo-rc. It splits the work into small, reviewable pull
requests merged to foo-rc (not main). I
review each PR and let Claude fix issues. After everything is
merged, test foo-rc again and merge to
main (example).
One issue here: Claude Code tended to create changes that were too
large. I’ll need to iterate on prompting to get more review-friendly
splits.
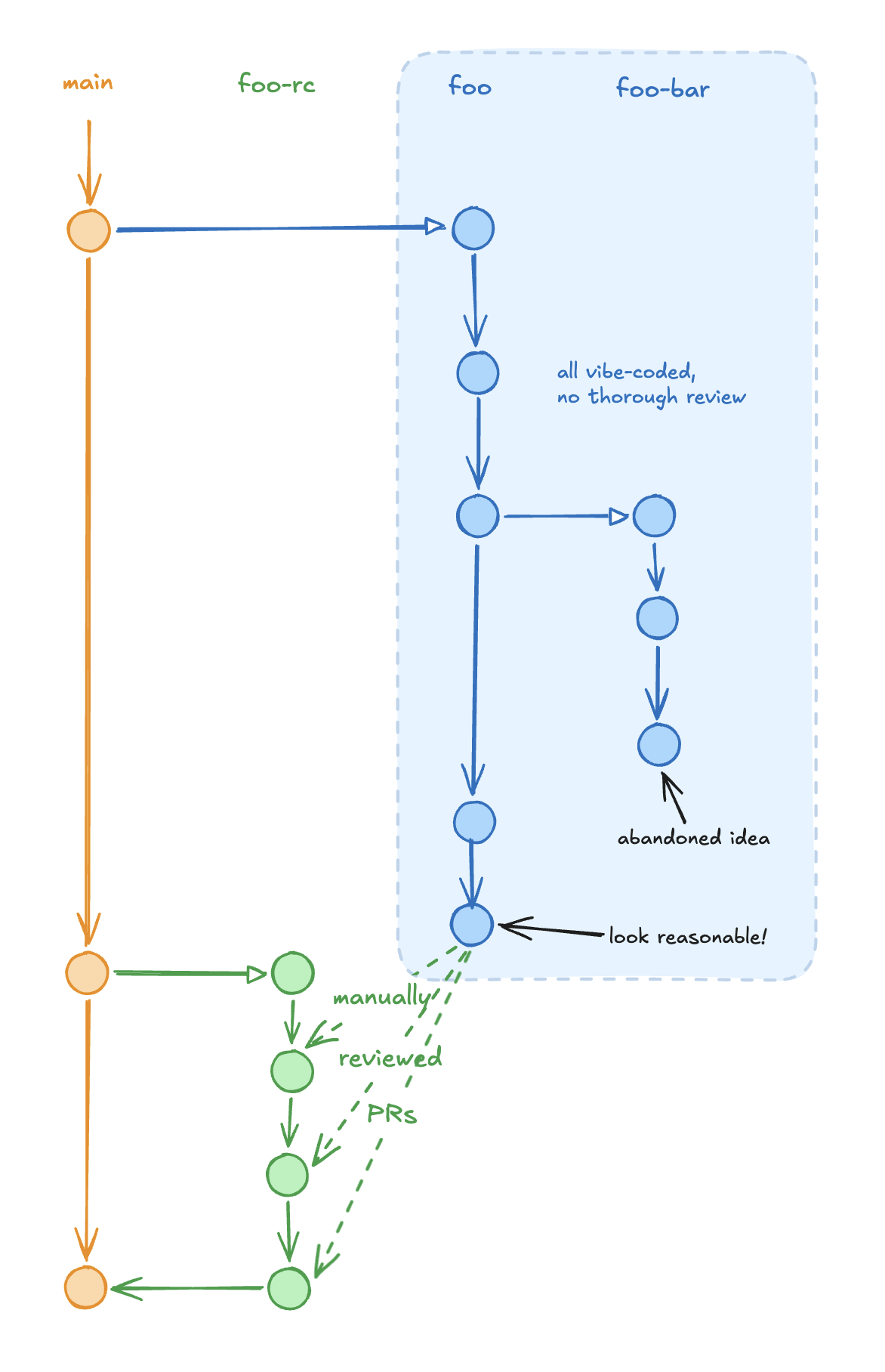
For smaller, targeted changes I tend to review it locally, not going through pull requests.
I never ran out of the 1M context window - I don’t think I ever went below 500k remaining.
I don’t use any complex setup beyond several custom commands:
/commit– the most used one. It writes detailed commit messages and checks that documentation is up to date. I commit very often - more than I would manually. AI assistance makes writing detailed commit messages nearly instant, they become the major source of context for future turns. This also helps with what some form of ‘code state invariant’: we should be able to continue working effectively if entire conversation/context is lost and only version control/working copy remains;/up2speed– read docs and recent commits to rebuild context. Useful when switching branches or after a restart. Less important with the 1M context window./oops <here's something that went wrong>– record that something went wrong and update CLAUDE.md so it doesn’t happen again. For example, Claude would repeatedly look for model files in the wrong place or use Python outside the virtual environment./hk– housekeeping. Check that documents, plans, and comments are consistent with the changes we made.
Problems encountered
- Major logic error. Despite being instructed, Claude computed KL-divergence over everything including the input prompt, giving too-good-to-be-true results for handoff. I caught it by looking at the result data and the size of saved logit files - not by reviewing the generated code (fix).
- Remote workflow. I could not figure out a good, intuitive, automated setup for “make changes, deploy to remote workstation, test there.”
- Inefficient code. Since we replay an existing token sequence (not generate new tokens), logits can be evaluated in large batches. Claude Code didn’t figure this out for the handoff scenario, making evaluation slow (fix).
- Skipping instructions. Despite explicit
instructions in
/commit, Claude Code would often skip the documentation update step, resulting in docs getting out of date (example).